Problem Statement
Design a news feed system similar to Facebook’s News Feed, where users can:
- See posts from their friends and followed pages
- Create new posts (text, images, videos)
- Like and comment on posts
- View their feed in real-time with minimal latency
Requirements Gathering
Functional Requirements
- Post Creation
- Users can create posts with text, images, and videos
- Posts should support likes and comments
- Posts should be timestamped
- Feed Generation
- Users should see posts from friends and followed pages
- Posts should be sorted by relevance and recency
- Feed should update in real-time
- Content Interaction
- Users can like and unlike posts
- Users can comment on posts
- Users can share posts
Non-Functional Requirements
- Performance
- Feed loading time < 2 seconds
- Real-time updates with < 5 seconds delay
- Smooth scrolling experience
- Scalability
- Support millions of active users
- Handle high write volume (posts, likes, comments)
- Support global access with minimal latency
- Reliability
- System should be highly available (99.99% uptime)
- No data loss
- Eventual consistency is acceptable
System Interface
Let’s define the key APIs our system will need:
# Post Creation API
def create_post(user_id: str, content: str, media_urls: List[str]) -> Post:
"""Creates a new post with optional media attachments."""
pass
# Feed Generation API
def get_feed(user_id: str, page_size: int, last_post_id: str = None) -> List[Post]:
"""Retrieves paginated feed for a user."""
pass
# Interaction APIs
def like_post(user_id: str, post_id: str) -> bool:
"""Likes/unlikes a post."""
pass
def add_comment(user_id: str, post_id: str, comment: str) -> Comment:
"""Adds a comment to a post."""
passCapacity Estimation
Let’s estimate the scale we need to support:
Traffic Estimates
- Daily Active Users (DAU): 500 million
- Average posts per user per day: 2
- Average feed requests per user per day: 20
- Average post size: 100 KB (including media)
Storage Estimates
Daily storage needed = DAU × posts_per_day × avg_post_size
= 500M × 2 × 100KB
= 100TB per dayBandwidth Estimates
Incoming traffic = DAU × posts_per_day × avg_post_size
= 500M × 2 × 100KB
= 100TB per day
≈ 9.3 Gbps
Outgoing traffic = DAU × feed_requests × avg_response_size
= 500M × 20 × 500KB
= 5000TB per day
≈ 463 GbpsHigh-Level System Design
Here’s the high-level architecture of our system:
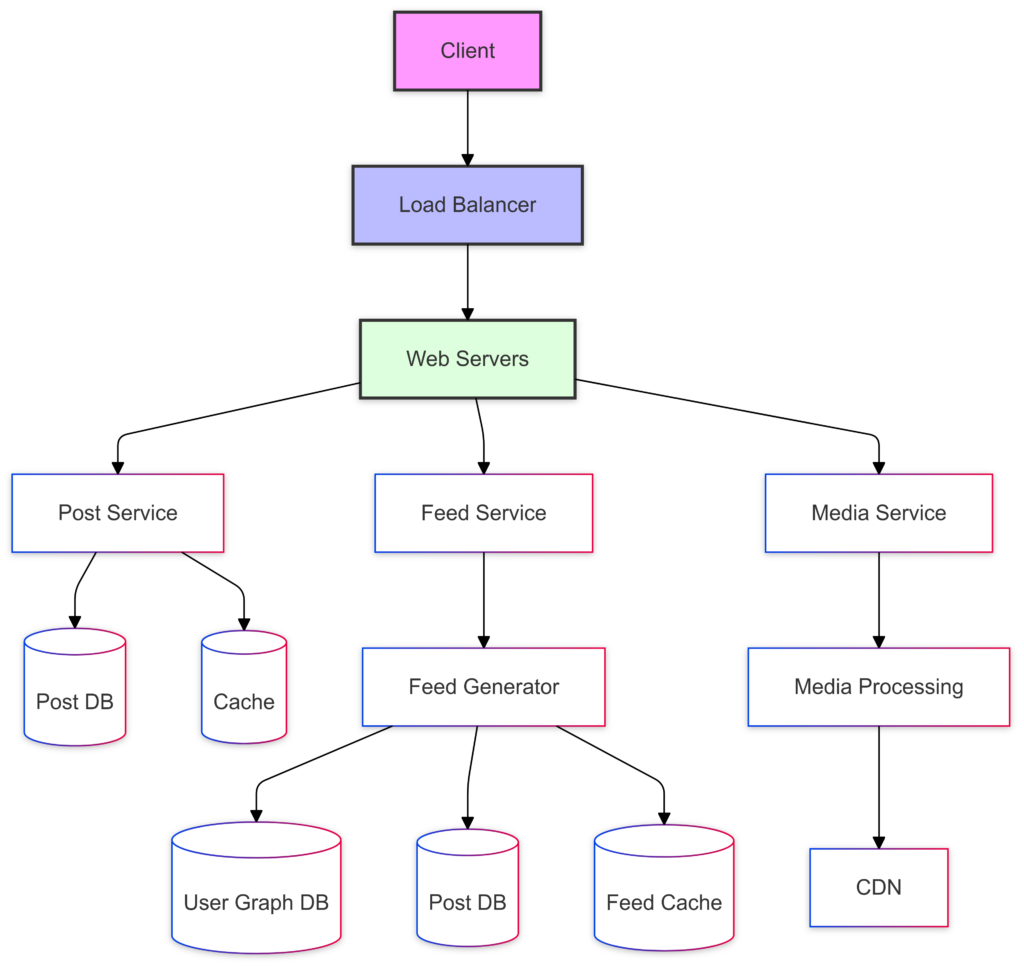
Key Components
- Load Balancer: Distributes incoming traffic across web servers
- Web Servers: Handle HTTP requests and basic request validation
- Post Service: Manages post creation and storage
- Feed Service: Generates and manages user feeds
- Media Service: Handles media upload and processing
- Cache Layer: Improves read performance
- CDN: Delivers media content efficiently
Post Service
The Post Service handles post creation and storage. Here’s its internal architecture:
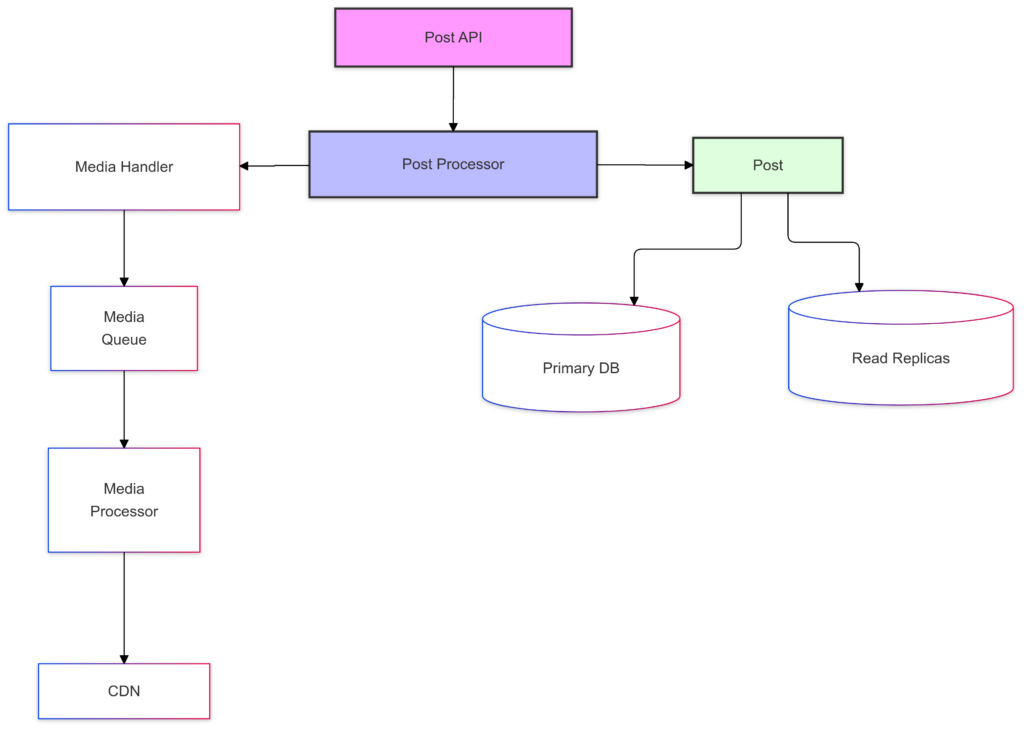
Data Model
-- Posts Table
CREATE TABLE posts (
post_id UUID PRIMARY KEY,
user_id UUID,
content TEXT,
created_at TIMESTAMP,
updated_at TIMESTAMP,
likes_count INT,
comments_count INT
);
-- Media Table
CREATE TABLE media (
media_id UUID PRIMARY KEY,
post_id UUID,
url TEXT,
type VARCHAR(10),
created_at TIMESTAMP,
FOREIGN KEY (post_id) REFERENCES posts(post_id)
);Feed Service
The Feed Service is responsible for generating and managing user feeds. It uses a combination of push and pull approaches:
Push Approach (Fanout)
- When a user creates a post, it’s immediately pushed to their followers’ feeds
- Good for users with few followers
- Implemented using a message queue system
Pull Approach
- Used for high-follower accounts
- Feeds are generated on-demand
- Reduces unnecessary computation
Here’s the feed generation algorithm:
def generate_feed(user_id: str, page_size: int) -> List[Post]:
# Get user's friends and followed pages
following = get_user_graph(user_id)
# Split into regular and high-follower accounts
regular, celebrity = split_by_follower_count(following)
# Get pre-computed feed for regular accounts
feed_items = get_from_feed_cache(user_id)
# Real-time merge for celebrity accounts
celebrity_posts = get_recent_posts(celebrity, limit=100)
# Merge and rank posts
feed = rank_and_merge(feed_items, celebrity_posts)
return feed[:page_size]Feed Generation Deep Dive
Ranking Algorithm
Posts are ranked using a combination of factors:
- Recency Score
The recency score algorithm is used to rank content based on how recently it was created. It’s commonly used in:- Social media feeds
- News aggregators
- Content recommendation systems
- Search result ranking
def calculate_recency_score(post_timestamp):
age_hours = (current_time - post_timestamp).total_hours()
return 1 / (1 + math.log(1 + age_hours))- Explanation of the calculate_recency_score
- Computes how old the content is in hours.
- Uses hours instead of seconds/minutes for more manageable numbers.
- Returns a value between 0 and 1 Newer content gets higher scores
- Score decreases logarithmically with age
- Engagement Score
The engagement score algorithm calculates content popularity based on user interactions. It’s commonly used in:- Social media feed ranking
- Content recommendation systems
- Trending topics detection
- Quality assessment of conten
def calculate_engagement_score(post):
likes_weight = 1
comments_weight = 1.5
shares_weight = 2
return (post.likes_count * likes_weight +
post.comments_count * comments_weight +
post.shares_count * shares_weight)- Explanation of the engagement score Algorithm
Action | Weight | Reasoning
Likes | 1.0 | Lowest effort, most common
Comments | 1.5 | More effort, shows better engagement
Shares | 2.0 | Highest value, extends content reach- Example Calculations:
# Post A: 100 likes, 10 comments, 5 shares
Score_A = (100 × 1) + (10 × 1.5) + (5 × 2) = 125
#Post B: 50 likes, 30 comments, 15 shares
Score_B = (50 × 1) + (30 × 1.5) + (15 × 2) = 125- Affinity Score
The affinity score algorithm measures the strength of connection between users based on their interactions. It’s commonly used in:- Social media feed personalization
- Content recommendation systems
- Friend/Follow suggestions
- News feed ranking
def calculate_affinity_score(user_id, post_author_id):
interaction_count = get_recent_interactions(user_id, post_author_id)
return math.log(1 + interaction_count)Explanation of the Affinity score Algorithm
interaction_count = get_recent_interactions(user_id, post_author_id)- Score Distribution:
- Retrieves recent interactions between two users
- Typically includes likes, comments, shares, profile views, etc.
return math.log(1 + interaction_count)- Logarithmic Scaling:
- Uses natural logarithm to dampen large numbers
- Adding 1 prevents log(0) undefined errors
Why Logarithmic Scaling Works
- Score Distribution:
Interactions | Score
0 | 0.000
1 | 0.693
5 | 1.792
10 | 2.398
100 | 4.615
1000 | 6.908- Benefits:
- Prevents domination by high-frequency interactions
- Maintains meaningful differences at lower ranges
- Reduces impact of outliers
Why Logarithmic Scaling Works
- Score Distribution:
Interactions | Score
0 | 0.000
1 | 0.693
5 | 1.792
10 | 2.398
100 | 4.615
1000 | 6.908</code>- Benefits:
- Prevents domination by high-frequency interactions
- Maintains meaningful differences at lower ranges
- Reduces impact of outliers
The final ranking combines these scores:
def calculate_final_score(post, user_id):
recency = calculate_recency_score(post.timestamp)
engagement = calculate_engagement_score(post)
affinity = calculate_affinity_score(user_id, post.author_id)
return (0.4 * recency +
0.4 * engagement +
0.2 * affinity)Data Storage
Storage Requirements
- Post Storage
- High write throughput
- Eventually consistent reads
- Support for efficient range queries
- User Graph Storage
- Fast graph traversal
- Frequent updates
- High read throughput
Storage Solutions
- Posts: Cassandra
- Excellent write performance
- Good horizontal scaling
- Suitable for time-series data
- User Graph: Neo4j
- Native graph database
- Efficient traversal queries
- ACID compliance
- Cache: Redis
- In-memory performance
- Support for complex data structures
- Built-in expiration
Scale & Performance
Caching Strategy
- Content Cache
- Feed caching is a critical component in social media and content delivery systems. This implementation demonstrates a cache-aside (lazy loading) pattern with Redis.
class FeedCache:
def get_feed(self, user_id: str) -> List[Post]:
cache_key = f"feed:{user_id}"
feed = redis.get(cache_key)
if not feed:
feed = generate_feed(user_id)
redis.setex(cache_key, 3600, feed) <em># 1-hour TTL</em>
return feedThe implementation uses a Time-Based Eviction (TTL = 3600 seconds) policy.
- Social Graph Cache
class GraphCache:
def get_following(self, user_id: str) -> Set[str]:
cache_key = f"following:{user_id}"
following = redis.get(cache_key)
if not following:
following = graph_db.get_following(user_id)
redis.setex(cache_key, 86400, following) <em># 24-hour TTL</em>
return followingPerformance Optimizations
- Feed Pagination
def get_paginated_feed(user_id: str, cursor: str = None):
page_size = 20
feed_items = []
if cursor:
<em># Get items after the cursor</em>
feed_items = get_feed_items_after(cursor, page_size)
else:
<em># Get first page</em>
feed_items = get_feed_items(user_id, page_size)
next_cursor = feed_items[-1].id if feed_items else None
return {
'items': feed_items,
'next_cursor': next_cursor
}- Read-Through Cache
class PostCache:
def get_post(self, post_id: str) -> Post:
cache_key = f"post:{post_id}"
post = redis.get(cache_key)
if not post:
post = db.get_post(post_id)
redis.setex(cache_key, 3600, post)
return postFollow-up Questions
How to handle feed updates?
We use WebSocket connections for real-time updates:
class FeedWebSocket:
def on_new_post(self, post: Post):
<em># Get online followers</em>
followers = get_online_followers(post.user_id)
<em># Push updates to connected clients</em>
for follower in followers:
if follower.is_connected():
follower.send_update(post)How to handle viral posts?
- Implement a viral post detector:
def detect_viral_post(post: Post) -> bool:
engagement_rate = post.engagement_count / post.impression_count
time_factor = (current_time - post.created_at).total_hours()
viral_score = engagement_rate / math.log(1 + time_factor)
return viral_score > VIRAL_THRESHOLD- Special handling for viral posts:
- Cache them aggressively
- Replicate them across regions
- Consider dedicated serving infrastructure
Conclusion
Designing a social media feed system involves balancing multiple competing requirements:
- Real-time updates vs system load
- Data consistency vs performance
- Storage efficiency vs read performance
Key takeaways:
- Use a hybrid push/pull approach for feed generation
- Implement intelligent caching strategies
- Design for horizontal scalability
- Consider trade-offs at each step
Remember to focus on these aspects during your interview:
- Clear requirement gathering
- Systematic approach to design
- Practical trade-off decisions
- Performance optimization strategies